프로그래밍 면접 문제 8 : Transform Word (문자 변환)
이 글은 블로그 http://www.ardendertat.com/의 프로그래밍 면접에 대한 글을 번역한 글입니다.
이전글 – 프로그래밍 면접 문제 7 : Binary Search Tree Check
원본 단어, 목표 단어 그리고 영어 사전이 주어지면, 원본 단어를 한번에 한 문자씩 변경/추가/제거를 통해서 목표 단어로 변환합니다. 단어를 변환하는 과정에서 나오는 중간 단어(intermediate word)는 모두 유효한 영어 단어여야 합니다. 중간 단어의 수가 가장 적은 변환 체인(transform chain)을 반환하는 함수를 작성합니다.
이 문제 역시 제가 가장 좋아하는 면접 문제 중 하나입니다. 특정 문제를 다른 방식으로 공식화하고 새로운 문제를 쉽고 우아하게 해결할 수 있는 방법을 보여주는 문제입니다. 여기서 우리는 이 문제를 그래프(graph) 문제로 공식화할 수 있으며 해결 방법은 너비 우선 탐색(breadth first search)을 통해서 얻을 수 있습니다.
먼저 주어진 사전(dictionary)을 미리 검색해두어야 합니다. 사전의 모든 단어를 그래프의 노드라고 하겠습니다. 그리고 특정 단어가 단일 변환(문자 변경, 문자 추가, 문자 삭제)을 통해서 다른 단어로 변환이 가능한 경우, 두 노드 사이에는 방향이 없는 에지(edge)가 존재합니다. 예를 들어 “bat”과 “cat” 사이에는 문자를 변경해서 서로의 단어를 만들 수 있기 때문에 에지(edge)가 존재합니다. 또한, “cat”과 “at” 사이에는 문자 제거를 통해서, “bat”과 “bart” 사이에는 문자를 추가하면 되기 때문에 에지(edge)가 존재합니다. 사전 전체를 미리 검색해서 규모가 큰 그래프를 생성해둘 수 있습니다. 한 단어에서 다른 단어로 변환이 잦은 경우에는, 이렇게 사전 전체를 미리 검색해두는데 드는 비용을 무시할 수 있습니다. 아래는 사전을 미리 읽어서 그래프를 생성하는 코드입니다. 그래프는 해시테이블(hashtable)이며 특정 단어를 키(key)로 가지고 이 단어에서 변환가능한 단어의 목록을 값(value)으로 저장합니다:
def constructGraph(dictionary):
graph=collections.defaultdict(list)
letters=string.lowercase
for word in dictionary:
for i in range(len(word)):
#remove 1 character
remove=word[:i]+word[i+1:]
if remove in dictionary:
graph[word].append(remove)
#change 1 character
for char in letters:
change=word[:i]+char+word[i+1:]
if change in dictionary and change!=word:
graph[word].append(change)
#add 1 character
for i in range(len(word)+1):
for char in letters:
add=word[:i]+char+word[i:]
if add in dictionary:
graph[word].append(add)
return graph
이제 각 에지(edge)가 단어 사이의 유효한 변환에 해당하는 그래프가 생겼습니다. 두 단어가 주어지면 시작 노드에서 너비 우선 탐색을 시작할 수 있고 목표 노드에 도달하면 두 단어 사이의 가장 짧은 변환을 얻을 수 있습니다 (시작, 목표 단어 중 하나 또는 두 단어 모두 사전에 존재하지 않을 수도 있습니다). 비 가중치 그래프(unweighted graph)에서 시작 노드가 탐색의 루트(root)노드인 경우, 너비 우선 탐색을 통해서 시작 노드에서 목표 노드까지의 최단 경로를 얻을 수 있습니다. 깊이 우선 탐색(depth first search)을 통해서는 최단 경로를 구할 수 없고, 노드가 매우 많기 때문에 최종 노드까지 탐색하는데 낭비되는 시간이 많아서 깊이 우선 탐색을 사용하지 않습니다. 다음은 이 접근 방법의 코드입니다. 위에서 생성한 그래프와 시작단어, 목표 단어를 입력 받습니다:
def transformWord(graph, start, goal):
paths=collections.deque([ [start] ])
extended=set()
#Breadth First Search
while len(paths)!=0:
currentPath=paths.popleft()
currentWord=currentPath[-1]
if currentWord==goal:
return currentPath
elif currentWord in extended:
#already extended this word
continue
extended.add(currentWord)
transforms=graph[currentWord]
for word in transforms:
if word not in currentPath:
#avoid loops
paths.append(currentPath[:]+[word])
#no transformation
return []
이 알고리즘의 복잡도는 그래프에서 두 단어 사이의 거리가 얼마나 먼 지에 따라서 결정됩니다. 최악의 경우, 문자 변환을 찾기위해서 그래프 전체를 탐색해야 할 수도 있습니다. 즉 그래프에 연결된 구성 요소가 2개 이상이거나, 원본 단어, 목표 단어 중 하나가 사전에 없거나 두 단어 모두 사전에 없는 경우도 있을 수 있습니다.
예를 들어서 사전에 cat, bat, bet, bed, at, ad, ed가 있다고 가정해 보겠습니다. 이 경우 변환 그래프는 다음과 같습니다:
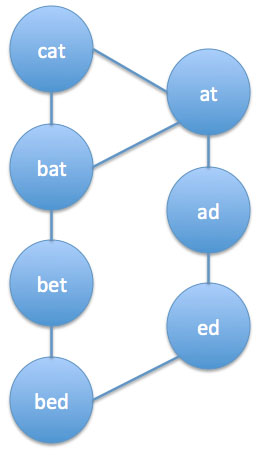
cat과 bed 사이의 변환에 대해서 최단 경로를 찾는다고 가정해 보겠습니다. 다음 그림은 어떻게 동작하는지 보여줍니다:
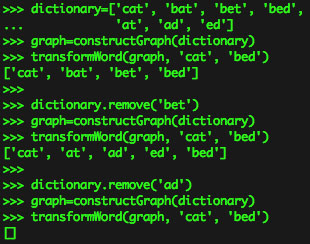
두 개의 경로가 있습니다. cat->bat->bet->bed 이 경로가 cat->at->ad->ed->bed 이 경로보다 더 짧습니다. ‘bet’ 노드를 삭제하면 첫 번째 경로가 유효하지 않게되고 최단 경로는 두 번째 경로가 됩니다. ‘ad’ 노드를 삭제하면 유효한 경로가 남지 않게 됩니다.
이 문제는 그래프의 힘과 그래프를 통해서 고전적인 탐색 알고리즘의 어려운 작업을 줄여서 문제를 공식화할 수 있다는 것을 증명해주는 문제입니다.
다음글 – 프로그래밍 면접 문제 9 : Convert Array