프로그래밍 면접 문제 23: Find Word Positions in Text
이 글은 블로그 http://www.ardendertat.com/의 프로그래밍 면접에 대한 글을 번역한 글입니다.
이전글 – 프로그래밍 면접 문제 22: Find Odd Occurring Element
텍스트 파일과 단어가 주어지면, 주어진 파일에서 주어진 단어의 위치를 찾는 문제입니다. 같은 파일 내 여러 단어의 위치를 찾으라는 요청을 받을 수 있습니다.
여러 요청에 대한 답을 구해야 하기 때문에 사전 계산(precomputation)이 유용할 수 있습니다. 이를 위해 텍스트 파일 내 모든 단어의 위치를 저장하는 자료 구조를 만듭니다. 이는 정보 검색에서 역색인(inverted index)이라고 알려져 있습니다. 역색인은 기본적으로 파일 내의 단어와 위치 사이의 매핑(mapping)입니다. 동작하는 검색 엔진을 실제 코드로 구현하는 방법을 설명해둔, how to implement a search engine 포스트에서 역색인에 대한 내용을 좀 더 자세히 살펴볼 수 있습니다.
역색일을 위해 해시테이블을 사용할 수 있습니다. 파일 내 단어가 키(key)가 되고 단어가 나타나는 위치의 배열이 값(value)디 됩니다. 따라서 파일 내의 모든 단어들을 모은 다음 파일의 위치와 함께 해시테이블에 저장합니다. 단어에는 대문자도 포함될 수 있지만, 역색인에서는 apple과 Apple을 분리된 항목으로 취급하지 않습니다. 따라서 모든 단어를 소문자로 변환하고 영문-숫자가 아닌 문제를 제거한 다음 공백을 기준으로 파일 내의 모든 단어를 구하는 함수를 작성합니다. 정규식(regular expression)을 이용하면 이를 쉽게 구현할 수 있습니다:
def getWords(text):
return re.sub(r'[^a-z0-9]',' ',text.lower()).split()
이 함수는 먼저 모든 단어를 소문자로 변환한 다음, 영문-숫자가 아닌 문자를 공백으로 대체하고 공백을 기준으로 단어를 나눕니다. 함수의 처리 결과로 원래의 순서대로 모든 단어를 얻을 수 있습니다. 그런 다음 이렇게 얻은 파일 내의 단어를 루프를 이용해서 역색인을 생성하고, 각 단어의 위치 목록을 해시테이블에 추가합니다.
def createIndex1(text):
index = collections.defaultdict(list)
words = getWords(text)
for pos, word in enumerate(words):
index[word].append(pos)
return index
색인(index)를 생성하고나면 쿼리(query)에 응답할 수 있습니다. 주어진 단어가 해시테이블 색인에 존재하는 경우, 해당 단어의 위치 배열을 반환합니다. 단어가 색인에 존재하지 않는 경우에는 해당 단어가 파일에 없다는 의미이기 때문에 빈 목록을 반환합니다. 코드는 다음과 같습니다:
def queryIndex1(index, word):
if word in index:
return index[word]
else:
return []
사실 이게 전부입니다. 단일 파일에 대한 검색 엔진을 구축한 것인데, 이를 여러 파일(웹페이지)에서 동작하도록 일반화하면 기본 검색 엔진을 갖출 수 있습니다. 색인 생성의 복잡도는 텍스트 내 단어 수에 비례하기 때문에 O(N)입니다. 색인 요청의 복잡도는 해시테이블 색인 내의 단순 조회 작업이기 때문에 일정한 복잡도인 O(1)입니다. 따라서 색인을 생성하고 단어 위치를 요청하는 작업은 모두 최적입니다. 공간 복잡도 또한 각 단어를 해시테이블의 키(key)로 사용하기 때문에, 단어의 수에 비례하여 O(N)입니다.
더 나은 솔루션
해시테이블을 역색인으로 이용하면 상당히 효율적입니다. 하지만 트라이(trie)라는 이름을 갖고 있고 prefix tree라고도 알려진, 텍스트에 좀 더 공간 효율이 좋은 자료 구조를 사용하면 좀 더 나은 해결 방법을 구할 수 있습니다. 트라이(trie)는 텍스트 저장 및 검색에 매우 효율적인 트리입니다. 트라이는 동일한 접두어를 가진 단어가 데이터를 공유하도록해서 공간을 절약합니다. 그리고 대부분의 언어에는 동일한 접두어를 공유하는 단어가 많이 포함되어 있습니다.
단어 subtree, subset, submit을 사용하는 예제를 이용해 이를 살펴보겠습니다. 해시테이블 색인에서 각 단어들은 각각 개별 키로 저장됩니다. 따라서 색인에서는 7 + 6 + 6 = 19 자의 공간이 필요합니다. 하지만 이 단어들은 모두 동일한 접두어 ‘sub’을 공유합니다. 트라이를 사용해 단어들이 색인에서 공통된 접두어를 공유하도록 하면, 이런 규칙에 따른 이득을 얻을 수 있습니다. 트라이 색인에서는 이 단어들이 7 + 3 + 3 = 13 자의 공간을 차지하기 때문에 색인의 크기를 약 30%가량 줄일 수 있습니다. 더 긴 접두어를 공유하는 단어들인 경우 더 많은 이득을 얻을 수 있습니다. author, authority, authorize를 예로 들 수 있습니다. 해시테이블 인덱스는 6 + 9 + 9 = 24 자의 공간을 사용하지만 트라이는 6 + 3 + 2 = 11 자의 공간만 사용하기 때문에 55%를 절약할 수 있습니다. 검색 엔진의 매우 큰 웹 색인을 고려해보면 색인의 크기를 10% 가량 줄이는 것은 매우 큰 이득이고, 이를 통해 테라바이트의 공간을 절약할 수 있으며 필요한 머신(machine)의 수를 1/10로 줄일 수 있습니다. 구글, 마이크로 소프트, 야후에서 수천 개의 머신이 사용된다는 점을 감안해볼 때 이는 엄청난 양입니다.
요약해보면, 텍스트 데이터에 대한 저장 및 검색 작업을 수행하는 동안 트라이를 사용하는 것은 매우 유용합니다. 트라이를 구현하는 방법이 이미 존재하지만, 이는 필요한 것보다 훨씬 복잡합니다. 따라서 간단하게 트라이를 직접 구현해 보겠습니다. 이를 직접 구현해보면 더 재미있고 유익한 정보가 될 것입니다.
트라이는 각 노드에서 문자를 키(key)로 저장하는 단순한 트리이며, 위의 예에서 값(value)의 경우 노드와 관련된 단어의 발생 위치가 됩니다. 노드와 관련된 단어는 트리의 루트에서 해당 노드까지 연결되는 문자입니다. 트리 내의 각 노드는 해당되는 단어가 있지만 모든 단어가 유효한 영어 단어는 아닙니다. 대부분은 중간 단어(Intermediate word)입니다. 주어진 텍스트에 나오는 단어들만 위치 데이터를 포함합니다. 이런 노드들을 터미널 노드라고 부릅니다. 특정 노드의 최대 자식 수는 텍스트에 나타나는 다른 문자의 수이고, 소문자로 된 영문-숫자만 고려하는 경우 36입니다. 다음은 노드의 구조입니다:
class Node:
def __init__(self, letter):
self.letter = letter
self.isTerminal = False
self.children = {}
self.positions = []
트라이 자료 구조는 이런 노드들로 구성되며 getItem, containes, ouput의 세가지 함수를 포함합니다. getItem 함수는 주어진 단어의 발생 위치를 반환하고 삽입에 사용되며, contains 함수는 해당 단어가 트라이에 있는지 없는지를 확인합니다. 그리고 output 함수는 트라이를 보기 좋은 방식으로 출력합니다. 먼저 getItem 함수를 이용해 기존 위치 목록을 가져온 다음, 단어의 새 위치를 단어 끝에 삽입하고 목록 끝에 새 위치를 추가합니다. 트라이에 없는 요소에 접근을 시도하면 collections.defaultdict와 비슷하게 자동으로 해당 요소를 생성합니다. getItem과 contains 함수의 코드는 매우 비슷합니다. 둘 모두 주어진 단어에 해당하는 노드에 찾을 때까지 트리를 탐색합니다. output 함수는 트라이 내 단어를 정렬된 순서로, 접두어 관계를 시각적으로 식별할 수 있는 방법으로 출력합니다. 다음은 완성된 구현입니다:
class Trie:
def __init__(self):
self.root=Node('')
def __contains__(self, word):
current=self.root
for letter in word:
if letter not in current.children:
return False
current = current.children[letter]
return current.isTerminal
def __getitem__(self, word):
current=self.root
for letter in word:
if letter not in current.children:
current.children[letter] = Node(letter)
current = current.children[letter]
current.isTerminal = True
return current.positions
def __str__(self):
self.output([self.root])
return ''
def output(self, currentPath, indent=''):
#Depth First Search
currentNode = currentPath[-1]
if currentNode.isTerminal:
word=''.join([node.letter for node in currentPath])
print indent + word + ' ' + str(currentNode.positions)
indent += ' '
for letter, node in sorted(currentNode.children.items()):
self.output(currentPath[:] + [node], indent)
새 createIndex, queryIndex 함수는 해시테이블에서 작성했던 함수와 비슷합니다:
def createIndex2(text):
trie = Trie()
words = getWords(text)
for pos, word in enumerate(words):
trie[word].append(pos)
return trie
def queryIndex2(index, word):
if word in index:
return index[word]
else:
return []
접두어를 공유하는 단어들로 구성된 예제 트라이를 살펴보겠습니다. 다음 예제는 데모를 위해 인위적으로 구성한 예제입니다: ‘us use uses used user users using useful username user utah’. output 함수는 다음과 같이 트라이를 출력합니다:
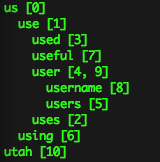
들여쓰기는 공유된 단어 접두어를 기반으로 구성됩니다. 예를 들어 used, useful, user는 모두 접두어 use를 공유합니다. 또한 username과 user는 user라는 접두어를 공유합니다. 하지만 us와 utah는 공유하는 접두어가(문자 u) 적절한 단어가 아니기 때문에 동일한 들여쓰기 레벨에 위치합니다. 단어의 값(value)은 텍스트의 발생 위치입니다.
트라이에 요소를 더하거나 탐색하는데 드는 복잡도는 해시테이블과 마찬가지로 O(1)입니다. 이는 트라이에 저장된 단어의 수에 영향을 받지 않고, 해싱(hashing)과 같이 단어의 문자 수에 영향을 받습니다. 그리고 특정 언어에 대한 단어의 최대 문자 수는 일정합니다. 영어 단어의 평균 문자 수는 4-5자이며 대부분 15자보다 짧습니다. 즉, 트라이에서 단어를 찾을 때는 일반적으로 4-5번의 작업이 소요되고 대부분 15번 보다 적은 양의 작업이 소요되며, 이는 저장된 단어의 수와 독립적입니다. 저장된 단어의 수가 수백만 또는 수십억 개가 될 수도 있지만 복잡도는 일정하게 유지됩니다. 이는 단어의 수에 비례하지 않고 일정하기 때문에 완벽합니다.
단일 파일에서 동작하는 기본 검색 엔진을 구현했고, 여러 파일을 검색할 수 있도록 쉽게 확장할 수 있기 때문에 개인적으로 가장 좋아하는 문제 중 하나입니다.
다음글 – 프로그래밍 면접 문제 24: Find Next Higher Number With Same Digits