프로그래밍 면접 문제 10 : Kth Largest Element in Array
이 글은 블로그 http://www.ardendertat.com/의 프로그래밍 면접에 대한 글을 번역한 글입니다.
이전글 – 프로그래밍 면접 문제 9 : Convert Array
정수 배열이 주어지면 정렬 된 순서로 k 번째 요소를 찾습니다 (서로 구별되는 요소 중 k 번째 요소가 아닙니다). 따라서 배열이 [3, 1, 2, 1, 4]이고 k가 3인 경우, 정렬 된 순서의 세 번째 요소는 2입니다 (그러나 구별되는 요소 중 세 번째 요소는 3입니다).
처음 떠오르는 접근 방법은 배열을 정렬한 다음, k 번째 요소를 반환하는 함수를 작성하는 것입니다. 이 접근 방법의 복잡도는 NlogN입니다. 여기서 N은 배열의 크기이며 최적의 방법은 분명히 아닙니다. 이 해결 방법은 필요한 것보다 더 많은 작업을 수행합니다. 이 방법은 모든 요소의 순서를 정렬한 다음 k번째로 절대적인 순서를 찾습니다. 하지만 이 문제를 해결하기 위해서는 k 번째로 큰 요소만 찾으면 됩니다. 그리고 우리는 선형 시간의 복잡도를 갖는 이상적인 해결 방법을 선호합니다.
퀵 정렬(QuickSort)에서 사용 된 선택 알고리즘을 사용할 수 있습니다. 이 알고리즘은 다음과 같이 동작합니다. 피벗(pivot)을 선택하고 왼쪽 및 오른쪽 하위 배열로 배열을 분할합니다. 피벗 값보다 작은 요소는 왼쪽 그룹에 저장하고, 피벗보다 크거나 같은 요소는 오른쪽 그룹에 저장합니다. 선택이 완료된 상태에서는 피벗만 정렬된 위치에 있습니다. 나머지 요소는 정렬되지 않았지만 피벗에 대한 상대 위치는 왼쪽 또는 오른쪽에 상관없이 정렬된 순서와 같습니다. 배열을 분할 한 후에 배열의 피벗 위치가 m이라고 가정해 보겠습니다. m이 k와 같으면 피벗은 정확히 우리가 찾고있는 k 번째 요소이므로 피벗 값을 반환합니다. m이 k보다 작으면 k 번째 요소는 오른쪽 하위 배열에 있습니다. 그렇지 않고 m이 k보다 크면 k번째 요소가 왼쪽 하위 배열에 있습니다. 따라서 재귀적으로 동일한 함수를 호출하는 방법을 이용해서 k 번째 요소를 찾을 수 있습니다. 아래 코드는 지금까지 설명한 내용을 명확하게 보여줍니다:
def partition1(arr, left, right, pivotIndex):
arr[right], arr[pivotIndex]=arr[pivotIndex], arr[right]
pivot=arr[right]
swapIndex=left
for i in range(left, right):
if arr[i] < pivot:
arr[i], arr[swapIndex] = arr[swapIndex], arr[i]
swapIndex+=1
arr[right], arr[swapIndex]=arr[swapIndex], arr[right]
return swapIndex
def kthLargest1(arr, left, right, k):
if not 1 <= k <= len(arr):
return
if left==right:
return arr[left]
while True:
pivotIndex=random.randint(left, right)
pivotIndex=partition1(arr, left, right, pivotIndex)
rank=pivotIndex-left+1
if rank==k:
return arr[pivotIndex]
elif k < rank:
return kthLargest1(arr, left, pivotIndex-1, k)
else:
return kthLargest1(arr, pivotIndex+1, right, k-rank)
파티션 함수는 위에서 설명한대로 배열을 두 개의 하위 배열로 나눕니다. 파티션에 사용된 피벗은 잠재적으로 최악의 성능을 피하기 위해 무작위로 균등하게 선택됩니다. 우리는 인덱스 내의 k 번째 요소를 검색합니다 [왼쪽, 오른쪽]. 왼쪽은 처음에는 0이고 오른쪽은 배열 길이에서 1을 뺀 값입니다. 분할 후 피벗의 순위가 k와 같으면 피벗 자체가 k번째 요소이므로 k를 반환합니다. 그렇지 않으면 재귀적으로 범위를 조정합니다. 피벗의 순위가 k보다 크면 왼쪽 하위 배열에서 검색을 계속해야하므로 새 배열 범위는 [left, pivotIndex – 1]이됩니다. 그렇지 않고 피벗의 순위가 k보다 작으면 오른쪽 하위 배열에서 검색을 계속되기 때문에 배열 범위는 [pivotIndex + 1, right]가 됩니다. 왼쪽 인덱스를 변경했기때문에 오른쪽 하위 배열을 검색하면 k의 값도 조정됩니다. 따라서 k의 새로운 값은 k-순위가 됩니다. 즉, 배열의 왼쪽 부분에서 제거 할 요소의 순위 값을 계산합니다.
이 접근방법의 평균 시간 복잡도는 O(N)입니다. 하지만 불행하게도 최악의 경우 복잡도는 O(N^2)입니다. 이는 배열을 잘 분할시키는 피봇을 제대로 선택하지 못해서 배열의 대부분의 요소들이 한쪽으로 치우치고 다른 쪽에는 배열 요소의 수가 아주 적게 배치되는 경우에 발생할 수 있습니다. 극단적인 경우, 가장 작은 수 또는 가장 큰 수를 피봇으로 선택하면, 한 쪽에 모든 배열 요소가 배치되고 다른 쪽에는 배열요소가 배치되지 않는 경우가 발생할 수도 있습니다. 이 결과로 각 반복 과정에서 1개의 요소만 제거할 수 있기 때문에, O(N^2)의 시간 복잡도를 갖게 됩니다. 이와는 반대로 최적의 성능은 배열을 완전히 반으로 나누는 피봇을 선택했을 때로, 이 경우 선형 시간 복잡도를 갖게 됩니다. 아래는 최상의 경우와 최악의 경우 사이의 재귀적 관계를 나타내며, 최상의 경우는 선형 복잡도를 최악의 경우 2차 함수의 복잡도를 갖습니다. 평균의 경우 선형 시간 복잡도를 갖습니다 (증명은 생략)
최상의 경우:
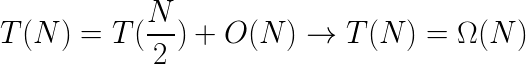

최악의 경우:
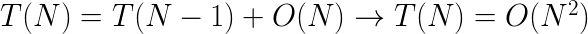
Median of Medians 알고리즘이라 불리는, 최악의 경우에도 선형 시간 복잡도를 갖는 매우 아름다운 알고리즘이 있습니다. 이 알고리즘은 다섯명의 위대한 컴퓨터 과학자 로버트 플로이드 (Floyd-Warshall 최단 경로 알고리즘), 본 프랫 (Pratt primality certificate), 로널드 라이베스트 (Ron Rivest, RSA 암호 알고리즘), 로버트 타잔 (Robert Tarjan, 그래프 알고리즘 및 데이터 구조)에 의해서 발견되었습니다. Median of medians는 선택 알고리즘을 수정한 버전으로, 피봇 선택을 향상시켜 최악의 경우에도 상당히 괜찮은 피봇을 고를 수 있도록 개선한 알고리즘 입니다. 이 알고리즘은 배열을 크기가 5인 그룹들로 나눕니다 (마지막 그룹은 크기가 5보가 작을 수 있습니다). 그 다음 각 그룹을 정렬하고 그 중간 요소를 선택해서, 각 그룹의 중간 값을 구합니다 (5개 요소를 정렬하는 복잡도는 무시해도 되는 정도입니다). 이 중간값 들의 중간 값을 재귀적으로 구한 다음, 이 중간 값들의 중간 값을 분할을 위한 피봇으로 선택합니다. 그런 다음 분할 이후 피봇의 순위에 따라서 왼쪽과 오른쪽 하위 배열을 재귀적으로 호출해서 이전의 선택 알고리즘과 유사한 방법을 진행합니다. partiton 함수는 약간 다른데, 위의 partition1 함수는 피봇의 인덱스를 입력으로 취하는 반면 아래의 partiton2 함수는 피봇 값을 입력으로 취합니다. 다음은 이에 대한 코드입니다:
def partition2(arr, left, right, pivot):
swapIndex=left
for i in range(left, right+1):
if arr[i]<pivot:
arr[i], arr[swapIndex] = arr[swapIndex], arr[i]
swapIndex+=1
return swapIndex-1
def kthLargest2(arr, left, right, k):
length=right-left+1
if not 1<=k<=length:
return
if length<=5:
return sorted(arr[left:right+1])[k-1]
numMedians=length/5
medians=[kthLargest2(arr, left+5*i, left+5*(i+1)-1, 3) for i in range(numMedians)]
pivot=kthLargest2(medians, 0, len(medians)-1, len(medians)/2+1)
pivotIndex=partition2(arr, left, right, pivot)
rank=pivotIndex-left+1
if k<=rank:
return kthLargest2(arr, left, pivotIndex, k)
else:
return kthLargest2(arr, pivotIndex+1, right, k-rank)
중간 값들의 중간 값을 피봇으로 사용하기 때문에 적어도 배열 요소보다 30퍼센트 크거나 아니면 작기 때문에 최악의 경우의 복잡도는 O(N)입니다. 따라서 최악의 경우에도 반복할 때마다 배열 요소의 일정 비율을 제거 할 수 있습니다. 이 결과는 이전 방법을 이용할 때도 원하던 결과얐지만, 달성하지 못했던 결과입니다. 최악의 경우에 대한 재귀 관계를 작성해서 선형 복잡도가 맞는지 확인하는 것 역시 가능합니다. N/5 는 중간 값의 중간 값을 피벗으로 선택하는 것에서 나온 것이고, 7N/10은 피벗이 최악의 분할 값을 생성 할 때를 나타냅니다.
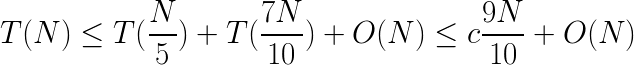
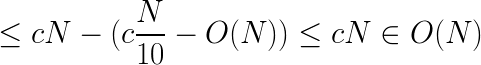
이 접근 방법은 매우 훌륭한 알고리즘이지만, 이전에는 보지 못했다면 면접 중에 어려움을 겪을 수 있습니다. 이 방법을 알아내는데는 적어도 5명의 위대한 생각이 필요했습니다. 이 방법은 알아두면 분명 좋은 방법이며 이 방법을 이해하는 데 드는 노력 역시 가치가 있습니다.
다음글 – 프로그래밍 면접 문제 11: All Permutations of String