자료구조를 처음 공부할 때는 보통 시간 복잡도(Big-O)를 중심으로 배우게 됩니다.
그래서 연결 리스트(linked list)는 삽입/삭제가 빠르고, 동적 배열(vector)은 중간 삽입이 느리다고 배우게 됩니다.
저도 처음에는 게임 엔진에서도 연결 리스트 같은 자료구조를 굉장히 많이 사용할 것 같다는 생각을 했던 것 같습니다.
왜냐하면 게임은 오브젝트 생성과 삭제가 굉장히 많고, 실시간으로 데이터가 계속 바뀌는 프로그램이기 때문입니다.
그런데 실제 게임 엔진 코드를 보다 보면 생각보다 동적 배열이 굉장히 많이 사용됩니다.
“삽입/삭제가 느리다고 배웠는데 왜 vector를 이렇게 많이 사용할까?”싶기도 합니다.
그리고 게임 엔진 구조나 성능 최적화를 조금 더 깊게 보기 시작하면, 생각보다 많은 문제들이 결국 Cache 이야기로 다시 연결됩니다.
Cache Miss, Cache Locality, Data Oriented Design 같은 이야기들이 등장하기 시작하는 것도 이 시점부터입니다.
CPU는 생각보다 굉장히 빠르다
예전에는 CPU 연산 자체가 굉장히 비싼 작업이었습니다.
그래서 최적화 이야기를 하면, 곱셈을 줄이거나, 나눗셈을 피하거나,
함수 호출을 줄이는 방식의 최적화를 굉장히 많이 이야기했습니다.
물론 이렇게 연산을 줄이는 작업은 지금도 중요합니다.
그런데 CPU는 정말 엄청나게 빠르게 동작합니다.
문제는 CPU가 항상 필요한 데이터를 즉시 가져올 수 있는 것은 아니라는 점입니다.
예를 들어 CPU가 어떤 데이터를 계산하려고 했는데,
그 데이터가 메인 메모리(RAM)에 있다면 CPU는 데이터를 기다려야 합니다.
그리고 이 기다리는 시간이 생각보다 굉장히 깁니다.
즉 현대 프로그램에서는 연산 자체보다,
메모리 접근이 병목이 되는 경우가 굉장히 많습니다.
게임 엔진이 Cache Locality를 중요하게 보는 이유도 결국 여기에 있습니다.
CPU는 데이터를 미리 가져오려고 한다
CPU는 굉장히 빠르지만,
RAM은 상대적으로 느립니다.
그래서 CPU는 필요할 것 같은 데이터를 미리 가까운 곳에 가져다 놓고 사용합니다.
이걸 CPU Cache라고 부릅니다.
배열을 순차적으로 읽는 상황을 생각해보겠습니다.
int values[1000];
CPU는 보통 데이터를 하나만 읽지 않습니다.
예를 들어 values[0]을 읽을 때, 주변 데이터도 같이 가져오는 경우가 많습니다.
왜냐하면 다음에도 근처 데이터를 사용할 가능성이 높다고 예상하기 때문입니다.
(네 맞습니다. CPU는 다음 동작을 미리 예측합니다. 캐시 지역성이 더 중요해지는 이유이기도 합니다.)
그리고 실제 프로그램에서도 연속된 메모리를 순차적으로 읽는 경우는 굉장히 많습니다.
따라서 메모리가 연속적으로 배치되어 있으면 CPU Cache 효율이 굉장히 좋아질 수 있습니다.
포인터가 많아지기 시작하면 문제가 달라진다
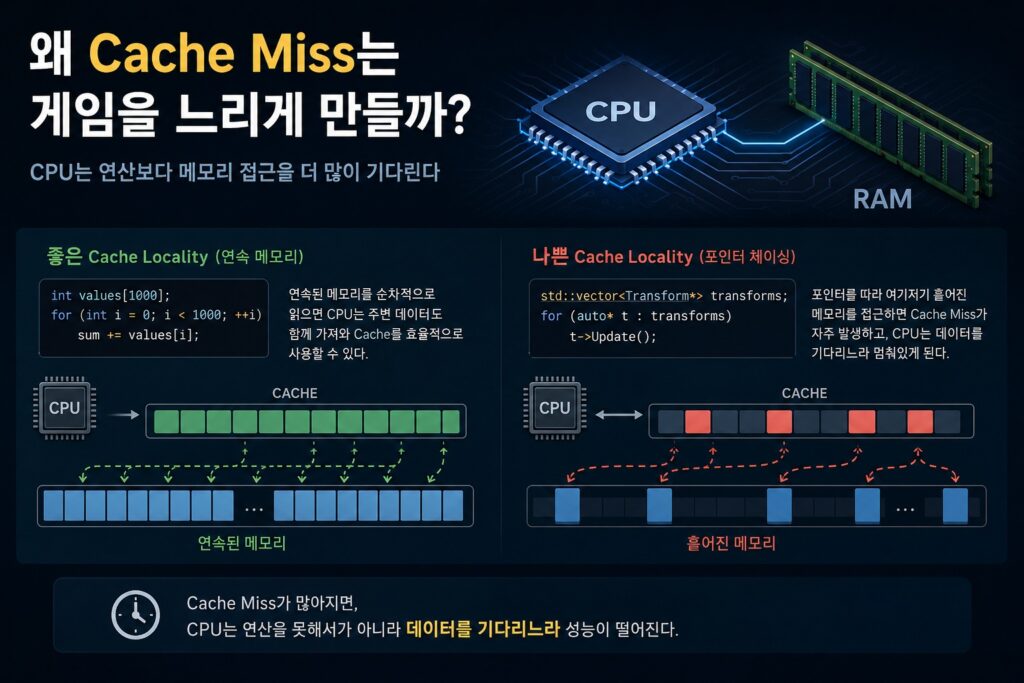
문제는 데이터가 항상 연속적으로 존재하는 것은 아니라는 점입니다.
예를 들어 아래와 같은 구조를 생각해보겠습니다.
std::vector<Transform*> transforms;
겉보기에는 vector라서 연속적인 구조처럼 보입니다.
하지만 실제로 연속적인 건 포인터 배열뿐입니다.
정작 Transform 데이터들은 메모리 여기저기에 흩어져 있을 가능성이 높습니다.
이런 경우라면, CPU는 데이터를 읽을 때마다 계속 새로운 메모리 위치로 이동해야 할 수도 있습니다.
그리고 이런 상황이 반복되면 CPU 캐시 효율이 급격히 떨어지기 시작합니다.
이걸 캐시 미스(Cache Miss)라고 부릅니다.
캐시 미스는 왜 느릴까?
CPU가 필요한 데이터를 캐시에서 찾지 못하면 결국 램까지 내려가서 데이터를 가져와야 합니다.
문제는 램 접근이 생각보다 굉장히 느리다는 점입니다.
그리고 요즘 CPU는 너무 빠르기 때문에 오히려 문제가 더 커집니다.
즉 CPU는 계산을 못해서 느린 게 아니라, 데이터가 도착하기를 기다리느라 멈춰있는 시간이 늘어나 느린 것입니다.
그래서 최근 성능 최적화에서는 “연산을 얼마나 줄일 것인가”보다,
“메모리를 어떻게 배치할 것인가”가 더 중요해지는 경우도 많습니다.
게임 엔진이 캐시 지역성(Cache Locality)을 중요하게 보는 이유도 결국 여기와 연결됩니다.
그리고 이 문제는 최근 게임 개발 업계의 면접 질문에도 자주 등장합니다.
게임 엔진은 vector를 굉장히 많이 사용한다
이런 이유 때문에 게임 엔진에서는 생각보다 vector를 굉장히 많이 사용합니다.
왜냐하면 실제 게임에서는 삽입/삭제보다 조회(Read)가 훨씬 많이 발생하기 때문입니다.
렌더링 시스템은 매 프레임마다 엄청난 양의 데이터를 반복해서 순회합니다.
Transform, Animation 데이터, Render Object, Particle 데이터 등을 예로들 수 있습니다.
그리고 이런 데이터들이 메모리 상에 연속적으로 배치되어 있으면 CPU는 데이터를 굉장히 효율적으로 읽을 수 있습니다.
반면, 연결 리스트처럼 데이터가 메모리 여기저기에 흩어져 있으면 CPU는 계속 새로운 메모리 위치를 따라가야 합니다.
그래서 이론적으로는 연결 리스트가 삽입/삭제에 유리할 수 있지만,
실제 게임 엔진에서는 vector가 훨씬 더 좋은 성능을 보여주는 경우가 많습니다.
최근 엔진 구조가 조금씩 바뀌기 시작했다
최근 ECS, Data Oriented Design, GPU Driven Rendering 같은 구조들이 등장한 이유도 결국 메모리 때문입니다.
여러분이 좋아하시는 설계 얘기를 잠깐 해보겠습니다.
예전에는 객체(Object) 중심으로 구조를 설계하는 경우가 많았습니다.
그런데 최근에는 데이터를 어떻게 연속적으로 배치할 것인가를 더 중요하게 보기 시작했습니다.
왜냐하면 요즘 CPU에서는 CPU 연산 자체보다 메모리 접근 방식 자체가 성능에 굉장히 큰 영향을 주기 때문입니다.
그래서 최근 엔진 구조를 보다 보면 결국 캐시 지역성(Cache Locality) 이야기가 계속 등장한다는 것을 느끼실 겁니다.
마무리
처음에는 캐시라는 개념이 단순히 CPU 내부의 작은 최적화 기능 정도로 느껴질 수도 있습니다.
저도 처음에는 “CPU 옆에 배치된 매우 빠른 메모리”정도로 생각했던 것 같습니다.
그런데 게임 엔진 구조나 성능 최적화를 조금 더 깊게 보기 시작하면,
생각보다 많은 문제들이 결국 캐시 이야기로 다시 연결됩니다.
왜 ECS가 등장했는지,
왜 vector를 선호하는지,
왜 allocator를 직접 구현하는지,
왜 Data Oriented Design이 중요해졌는지도 결국 다 같은 이야기입니다.
그리고 이런 구조들을 보다 보면,
최신 게임 엔진은 결국 “코드를 어떻게 작성할 것인가”보다,
“데이터를 메모리에 어떻게 배치할 것인가”가 더 중요해지는 방향으로 조금씩 이동하고 있다는 것을 느끼실 겁니다.
다음 글에서는 왜 게임 엔진들이 allocator와 memory pool을 직접 구현하는지,
그리고 일반적인 Heap Allocation이 어떤 문제를 만들 수 있는지 조금 더 자세히 정리해보겠습니다.
👉 게임 엔진 구조를 더 깊이 이해하고 싶다면
아래 강의를 통해 직접 구현해보는 것을 추천드립니다.

👉 C++로 만드는 게임 엔진 프레임워크 강의 바로가기