들어가며
이전 글에서는 C++ allocator의 기본 개념을 정리했습니다.
allocator는 쉽게 말하면 메모리 할당 정책을 컨테이너와 분리하기 위한 구조입니다.
그런데 allocator는 설명만 들으면 조금 추상적으로 느껴질 수 있습니다.
이번 글에서는 직접 구현한 동적 배열 Vector에 allocator를 적용해보겠습니다.
다음 코드는 std::vector와 비슷한 형태로 간단히 구현해본 동적 배열 코드입니다.
#pragma once
#include <iostream>
template <typename T>
class Vector
{
public:
Vector()
{
ReAllocate(2);
}
~Vector()
{
if (data != nullptr)
{
delete[] data;
}
}
void PushBack(const T& value)
{
if (size == capacity)
{
ReAllocate(capacity * 2);
}
data[size] = value;
size++;
}
void PushBack(T&& value)
{
if (size == capacity)
{
ReAllocate(capacity * 2);
}
data[size] = std::move(value);
size++;
}
void Erase(int index)
{
// 인덱스 검사.
if (index < 0 || index >= size)
{
return;
}
// 삭제하려는 인덱스 이후의 값을 왼쪽으로 밀어서 저장.
for (int ix = index; ix < size - 1; ++ix)
{
data[ix] = std::move(data[ix + 1]);
}
// 크기 감소 처리.
--size;
// 마지막 위치 값 정리.
data[size] = T{};
}
int Size() const
{
return size;
}
int Capacity() const
{
return capacity;
}
const T& operator[](int index) const
{
if (index >= size)
{
__debugbreak();
}
return data[index];
}
T& operator[](int index)
{
if (index >= size)
{
__debugbreak();
}
return data[index];
}
private:
void ReAllocate(int newCapacity)
{
// 1. allocate a new block of memory.
// 2. copy/move old elements into new block.
// 3. delete.
T* newBlock = new T[newCapacity];
if (newCapacity < size)
{
size = newCapacity;
}
for (int ix = 0; ix < size; ++ix)
{
// newBlock[ix] = data[ix];
newBlock[ix] = std::move(data[ix]);
}
delete[] data;
data = newBlock;
capacity = newCapacity;
}
private:
T* data = nullptr;
int size = 0;
int capacity = 0;
};
이 코드는 동적 배열의 기본 구조를 이해하기에는 좋습니다.
하지만 allocator 관점에서 보면 몇 가지 개선 가능한 지점이 있습니다.
이번 글에서는
- 기존 Vector 코드의 문제점
- new[] / delete[] 방식의 한계
- raw memory와 객체 생성의 분리
- std::allocator 적용 방법
- PushBack / Erase / ReAllocate 개선
순서로 정리해보겠습니다.
기존 코드의 핵심 구조
현재 Vector는 내부적으로 다음 정보를 가지고 있습니다.
T* data = nullptr; int size = 0; int capacity = 0;
각 변수의 의미는 다음과 같습니다.
data: 실제 데이터를 저장하는 메모리 주소size: 현재 저장된 원소 개수capacity: 확보해둔 전체 공간 개수
이 구조는 std::vector의 기본 개념과도 비슷합니다.
size
→ 실제 사용 중인 원소 수
capacity
→ 미리 확보해둔 메모리 공간
입니다.
현재 ReAllocate 코드
메모리가 부족해지면 ReAllocate()를 호출해서 새로운 공간에 더 합니다.
void ReAllocate(int newCapacity)
{
// 1. allocate a new block of memory.
// 2. copy/move old elements into new block.
// 3. delete.
T* newBlock = new T[newCapacity];
if (newCapacity < size)
{
size = newCapacity;
}
for (int ix = 0; ix < size; ++ix)
{
// newBlock[ix] = data[ix];
newBlock[ix] = std::move(data[ix]);
}
delete[] data;
data = newBlock;
capacity = newCapacity;
}
겉으로 보면 자연스럽습니다.
새 배열을 만들고, 기존 데이터를 복사한 뒤, 기존 배열을 삭제합니다.
하지만, 이 코드는 int 같은 단순 타입에서는 어느 정도 동작해도, 일반적인 C++ 객체에는 위험할 수 있습니다.
문제 1. new T[]는 capacity만큼 객체를 전부 생성한다
다음 코드를 보겠습니다.
T* newBlock = new T[newCapacity];
이 코드는 단순히 메모리만 확보하는 코드가 아닙니다.
newCapacity 개수만큼 T 객체를 전부 기본 생성합니다.
즉, 메모리 확보 + T 객체 newCapacity개 생성이 함께 발생합니다.
예를 들어 capacity가 1000이라면, 실제로 size가 10이어도 T 객체 1000개가 생성됩니다.
하지만 동적 배열에서 진짜 필요한 것은 다음과 같습니다.
capacity만큼 메모리 공간은
확보 size만큼만 실제 객체 생성
이 차이가 중요합니다.
문제 2. 기본 생성자가 없는 타입을 담기 어렵다
new T[newCapacity]는 모든 원소를 기본 생성합니다.
따라서 T에 기본 생성자가 없다면 문제가 됩니다.
예를 들어
class Player
{
public:
Player(int hp)
: hp(hp)
{
}
private:
int hp = 0;
};
이 타입은 기본 생성자가 없습니다.
그런데 현재 Vector는 내부에서
new T[newCapacity]
를 호출하므로, Player를 담기 어렵습니다.
Vector<Player> players;
이런 형태가 문제가 될 수 있습니다.
즉, 현재 Vector는 기본 생성 가능한 타입에 의존하는 구조입니다.
문제 3. 사용하지 않는 공간에도 객체가 존재한다
동적 배열에서 capacity는 미리 확보한 공간입니다.
하지만 현재 구조에서는
T* newBlock = new T[newCapacity];
때문에 capacity만큼 객체가 전부 생성됩니다.
즉,
size = 3 capacity = 8
인 상황에서도, 실제로는 T 객체가 8개 생성되어 있습니다.
하지만 논리적으로는 3개만 사용 중입니다.
이 구조는
- 불필요한 생성 비용
- 불필요한 소멸 비용
- 객체 생명주기 관리의 부정확함
문제를 만들 수 있습니다.
핵심 문제: 메모리 확보와 객체 생성이 분리되어 있지 않다
현재 코드의 핵심 한계는 이것입니다.
메모리 확보와 객체 생성이 분리되어 있지 않습니다.
new T[]는:
- 메모리 확보
- 객체 생성
을 동시에 수행합니다.
하지만 std::vector 같은 컨테이너는 보통 이런 방식으로 동작합니다.
raw memory 확보
↓
PushBack 시점에 필요한 위치에 객체 생성
↓
Erase / Clear 시점에 객체 소멸
↓
Vector 소멸 시 raw memory 해제
즉, 메모리 공간과 객체 생명주기를 분리해서 관리합니다.
이 구조를 구현하기 위해 allocator를 사용할 수 있습니다.
allocator가 필요한 이유
지금까지 설명한 기존 Vector 구조와 allocator 기반 구조 차이를 그림으로 정리해보면 다음과 같습니다.
핵심은 allocator는 단순 메모리 할당기가 아니라, 메모리 확보와 객체 생명주기를 분리하기 위한 구조라는 점입니다.
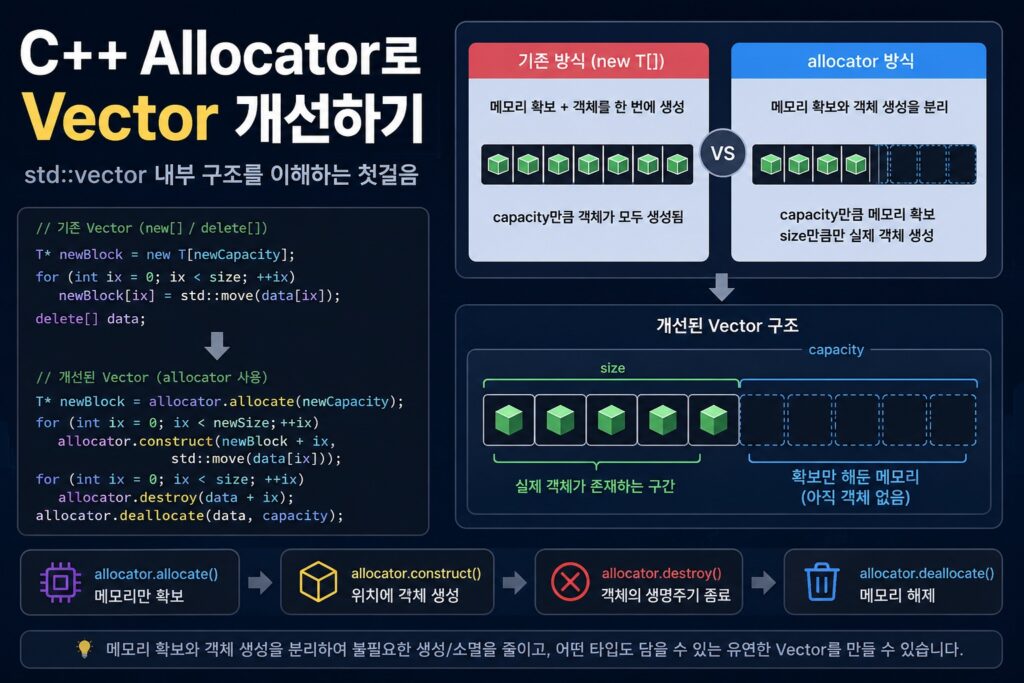
allocator는 메모리 확보와 객체 생명주기를 분리해서 다룰 수 있게 해줍니다.
대표적으로 다음 작업을 수행합니다.
- allocate // raw memory 확보
- construct // 확보한 메모리에 객체 생성
- destroy // 객체 소멸자 호출
- deallocate // raw memory 해제
즉,
- new T[]: 모든 객체를 한 번에 생성
- allocator: 메모리 확보와 객체 생성을 분리
라고 이해하면 됩니다.
allocator를 적용한 Vector 기본 구조
이제 Vector에 allocator를 추가해보겠습니다.
#pragma once
#include <iostream>
#include <memory>
#include <utility>
template <typename T, typename Allocator = std::allocator<T>>
class Vector
{
public:
Vector()
{
ReAllocate(2);
}
~Vector()
{
Clear();
if (data != nullptr)
{
allocator.deallocate(data, capacity);
}
}
private:
T* data = nullptr;
int size = 0;
int capacity = 0;
Allocator allocator;
};
기존과 달라진 점은 다음입니다.
template <typename T, typename Allocator = std::allocator<T>>
이제 Vector는 allocator 타입을 템플릿 인자로 받을 수 있습니다.
기본값은 std::allocator<T>입니다.
즉, 별도로 allocator를 지정하지 않으면 기본 allocator를 사용합니다.
소멸자에서 해야 할 일
기존에는 소멸자에서 단순히 delete[]를 호출했습니다.
delete[] data;
하지만, allocator를 사용하면 이렇게 하면 안 됩니다.
왜냐하면, 메모리 안에 생성된 객체만 직접 소멸시키고, 그 후 raw memory를 해제해야 하기 때문입니다.
그래서 소멸자는 다음처럼 작성합니다.
~Vector()
{
Clear();
if (data != nullptr)
{
allocator.deallocate(data, capacity);
}
}
여기서 Clear()는 실제 생성된 객체만 파괴합니다.
Clear 구현
void Clear()
{
for (int ix = 0; ix < size; ++ix)
{
allocator.destroy(data + ix);
}
size = 0;
}
이 코드는 현재 Vector에 실제로 들어 있는 객체만 destroy합니다.
즉, capacity 전체가 아니라, size만큼만 소멸자를 호출합니다.
이게 중요합니다.
allocator로 확보한 메모리 중에서 실제로 객체가 생성된 위치는 0 ~ size - 1까지입니다.
PushBack 구현
이제 PushBack을 수정해보겠습니다.
먼저 const 참조 버전입니다.
void PushBack(const T& value)
{
if (size == capacity)
{
ReAllocate(capacity * 2);
}
allocator.construct(data + size, value);
size++;
}
기존에는 다음처럼 대입했습니다.
data[size] = value;
하지만, allocator 방식에서는 아직 data + size 위치에 객체가 생성되어 있지 않습니다.
그래서 대입이 아니라 그 위치에 객체를 생성해야 합니다.
즉, 아직 객체가 존재하지 않는 raw memory 위치에 생성자를 직접 호출하는 개념에 가깝습니다.
아래 코드가 그 역할을 담당합니다.
allocator.construct(data + size, value);
PushBack 이동 버전
이동 버전도 비슷합니다.
void PushBack(T&& value)
{
if (size == capacity)
{
ReAllocate(capacity * 2);
}
allocator.construct(data + size, std::move(value));
size++;
}
이 코드는 rvalue를 받아서, 새 위치에 이동 생성합니다.
즉, 복사가 아니라 이동을 통해 객체를 생성할 수 있습니다.
ReAllocate 구현
가장 중요한 함수는 ReAllocate()입니다.
allocator를 사용하는 핵심이 여기에 있습니다.
void ReAllocate(int newCapacity)
{
T* newBlock = allocator.allocate(newCapacity);
int newSize = size;
if (newCapacity < newSize)
{
newSize = newCapacity;
}
for (int ix = 0; ix < newSize; ++ix)
{
allocator.construct(newBlock + ix, std::move(data[ix]));
}
for (int ix = 0; ix < size; ++ix)
{
allocator.destroy(data + ix);
}
if (data != nullptr)
{
allocator.deallocate(data, capacity);
}
data = newBlock;
size = newSize;
capacity = newCapacity;
}
여기서 중요한 점은 allocator.allocate()는 메모리만 확보한다는 것입니다.
아직 해당 위치에는 T 객체가 생성되지 않은 상태입니다.
따라서 이후에 allocator.construct()를 사용해서 실제로 객체를 생성하게 됩니다.
이 함수는 다음 순서로 동작합니다.
새 raw memory 확보
↓
기존 객체를 새 메모리에 이동 생성
↓
기존 객체 destroy
↓
기존 raw memory 해제
↓
data / size / capacity 갱신
객체의 이동 생성자를 통해 기존의 데이터를 안전하게 옮깁니다.
Erase 구현
기존 Erase는 삭제 후 마지막 위치에 기본값을 대입했습니다.
data[size] = T{};
하지만, allocator 방식에서는 마지막 객체를 명확하게 destroy하는 것이 좋습니다.
개선된 코드는 다음과 같습니다.
void Erase(int index)
{
if (index < 0 || index >= size)
{
return;
}
for (int ix = index; ix < size - 1; ++ix)
{
data[ix] = std::move(data[ix + 1]);
}
allocator.destroy(data + size - 1);
--size;
}
이 코드는 삭제 이후 뒤쪽 객체들을 앞으로 이동시킵니다.
그리고 마지막 위치에 남아 있는 객체를 destroy합니다.
즉, move assignment를 통해 데이터를 앞으로 당기고, 논리적으로 제거된 마지막 객체의 생명주기를 명확하게 정리합니다.
Erase 구현에서 주의할 점
위 코드는 학습용으로는 흐름을 이해하기 좋습니다.
다만, 실제 STL 수준의 구현은 훨씬 더 복잡합니다.
- 예외 안정성
- trivial type 최적화
- move assignment 사용 여부
- allocator_traits 사용
등을 모두 고려해야 하기 때문입니다.
이번 글의 목적은 완전한 std::vector를 만드는 것이 아니라
allocator를 통해 메모리와 객체 생명주기를 분리하는 원리를 이해하는 것입니다.
전체 코드
정리하면 다음과 같습니다.
#pragma once
#include <iostream>
#include <memory>
#include <utility>
template <typename T, typename Allocator = std::allocator<T>>
class Vector
{
public:
Vector()
{
ReAllocate(2);
}
~Vector()
{
Clear();
if (data != nullptr)
{
allocator.deallocate(data, capacity);
}
}
void PushBack(const T& value)
{
if (size == capacity)
{
ReAllocate(capacity * 2);
}
allocator.construct(data + size, value);
size++;
}
void PushBack(T&& value)
{
if (size == capacity)
{
ReAllocate(capacity * 2);
}
allocator.construct(data + size, std::move(value));
size++;
}
void Erase(int index)
{
if (index < 0 || index >= size)
{
return;
}
for (int ix = index; ix < size - 1; ++ix)
{
data[ix] = std::move(data[ix + 1]);
}
allocator.destroy(data + size - 1);
--size;
}
void Clear()
{
for (int ix = 0; ix < size; ++ix)
{
allocator.destroy(data + ix);
}
size = 0;
}
int Size() const
{
return size;
}
int Capacity() const
{
return capacity;
}
const T& operator[](int index) const
{
if (index >= size)
{
__debugbreak();
}
return data[index];
}
T& operator[](int index)
{
if (index >= size)
{
__debugbreak();
}
return data[index];
}
private:
void ReAllocate(int newCapacity)
{
T* newBlock = allocator.allocate(newCapacity);
int newSize = size;
if (newCapacity < newSize)
{
newSize = newCapacity;
}
for (int ix = 0; ix < newSize; ++ix)
{
allocator.construct(newBlock + ix, std::move(data[ix]));
}
for (int ix = 0; ix < size; ++ix)
{
allocator.destroy(data + ix);
}
if (data != nullptr)
{
allocator.deallocate(data, capacity);
}
data = newBlock;
size = newSize;
capacity = newCapacity;
}
private:
T* data = nullptr;
int size = 0;
int capacity = 0;
Allocator allocator;
};
allocator 적용 후 달라진 점
기존 Vector 코드에서는 아래와 같이 new와 delete를 사용해 메모리를 관리했습니다.
new T[] delete[]
allocator 적용 후에는 allocator를 사용해 메모리를 관리하도록 변경했습니다.
allocate construct destroy deallocate
이 차이는 매우 중요합니다.
이제 Vector는
- 메모리 확보
- 객체 생성
- 객체 소멸
- 메모리 해제
를 분리해서 처리합니다.
이것이 STL 컨테이너가 allocator를 사용하는 핵심 이유입니다.
왜 이 구조가 std::vector와 비슷한가?
std::vector 역시 내부적으로 미리 메모리를 확보해두고, 필요한 위치에 객체를 생성합니다.
capacity만큼 메모리를 확보하고 size만큼 객체를 생성하는 구조입니다.
이 점이 중요합니다.
capacity가 100이라고 해서 객체 100개가 전부 생성되어 있는 것이 아닙니다.
실제로 생성된 객체는 size만큼입니다.
실무 관점에서의 의미
allocator를 사용하면 단순히 STL 흉내를 내는 것에서 끝나지 않습니다.
나중에는 allocator를 바꿔서
- Pool Allocator
- Linear Allocator
- Frame Allocator
- Tracking Allocator
같은 구조로 확장할 수 있습니다.
컨테이너 코드는 유지하면서, 메모리 정책만 교체할 수 있습니다.
이게 allocator를 분리하는 진짜 이유입니다.
핵심 정리
- 기존
new T[]방식은 메모리 확보와 객체 생성을 동시에 수행합니다. memset,memcpy는 일반 객체 타입에 위험할 수 있습니다.- allocator는 메모리 확보와 객체 생명주기를 분리합니다.
allocate는 raw memory만 확보합니다.construct는 확보된 메모리에 객체를 생성합니다.destroy는 객체의 소멸자를 호출합니다.deallocate는 raw memory를 해제합니다.- 이 구조는
std::vector의 핵심 동작 방식과 연결됩니다.
참고
C++ 20 이후 버전에서는 allocator.construct() 대신 std::allocator_traits를 사용하는 방식이 권장됩니다.
본 글에서는 C++ 14/17 수준에서 코드를 작성했습니다.
std::allocator_traits<Allocator>::construct(...) std::allocator_traits<Allocator>::destroy(...)
이번 글에서는 allocator의 동작 원리를 이해하기 위해
조금 단순화된 형태로 설명합니다.
마무리
allocator를 직접 컨테이너에 적용해보면, 왜 STL 컨테이너가 단순히 new[]와 delete[]만 사용하지 않는지 이해할 수 있습니다.
핵심은 메모리와 객체 생명주기를 분리해서 관리하는 것입니다.
이 구조를 이해하면
- std::vector의 내부 동작
- placement new
- move semantics
- custom allocator
- 게임 엔진 메모리 시스템
이 훨씬 자연스럽게 연결됩니다.
allocator는 단순 문법이 아니라 C++ 컨테이너와 게임 엔진 메모리 구조를 이해하기 위한 중요한 연결 지점이라고 볼 수 있습니다.
👉 게임 엔진 구조를 더 깊이 이해하고 싶다면
아래 강의를 통해 직접 구현해보는 것을 추천드립니다.

👉 C++로 만드는 게임 엔진 프레임워크 강의 바로가기